"Research data management concerns the organisation of data, from its entry to the research cycle through to the dissemination and archiving of valuable results. It aims to ensure reliable verification of results, and permits new and innovative research built on existing information."
Whyte, A., Tedds, J. (2011). ‘Making the Case for Research Data Management’. DCC Briefing Papers. Edinburgh: Digital Curation Centre

Research data management is not ‘else’ than research, but is an integral and indispensable part of the research process. There are a number of reasons why there is an emphasis on research data management and FAIR data, first of all the possibility to reproduce a research result being able to benefit from all necessary information and documentation: it makes the process efficient, brings many diverse benefits, and meets the requirements of funders and institutions. Importantly, data management covers all stages of research, from project structuring to preservation and dissemination of final results.
1. Planning and structuring
When preparing a new research project, planning in advance is crucial: it is important not only to think about the questions you will address with your research and its impact, but also to focus on the data your will produce and the different phases your data will go through the project. Thinking about data in advance (even before strarting to produce it) helps to manage it better: this applies both to the data generated by the project and to the data produced by others that are reused for research. Writing a Data Management Plan (DMP) can be really helpful and can facilitate the retrieval and understanding and reuse of your data in the future. Importantly, when writing a DMP remember to: comply with FAIR principles, examine research data use regulations that may influence your project, check compliance with the rules on ethical principles privacy and intellectual property, and identify rights ownership on data.
2. Collection and organization
Firstly define standard methodologies and processes and pay attention in structuring your data logically, ordering it into organized datasets and entitling it according to standard naming conventions. Importantly, as you start collecting data, take care of storing your datasets in appropriate storage spaces providing periodic backups and ensure that you avoid keeping everything in just one place. To guarantee the transparency and traceability of your methods - and, thus, the reproducibility of your results -, in this phase it is also essential to collect all the documentation necessary to understand the data. Start by preparing an exhaustive README file, keeping also account of the adequate metadata supporting your data and the most suitable formats to use. You can collect harmonized and persistent documentation by using tools like electronic lab notebook, for example.
3. Security and preservation
In this phase it is essential to ensure the integrity of your research. This means both to guarantee its quality - thus make sure that you always carry out a quality control and check for eventual alteration on your final data - and to certify its "physical" preservation. Importantly, it is crucial to provide security measures and to use appropriate storage tools for the long term to prevent data loss and leaks, and to mitigate the risk of unauthorized access by using proper infrastructures and setting up adequate processes (indeed, when using or generating personal data this process is a legal obligation). Usually, it is advised to consider at least 10 years for proper data storage: this allows for reproducibility and reuse; and it may also be required explicitly by funders or publishers. Indeed, the choice of the right storage tool (i.e., a data repository) is also importantly related to the final phase of data sharing.
4. Sharing and disseminating
Sharing and making data accessible allows researchers to build upon your work and increases its visibility; plus, it is increasingly becoming part of the requirements of funders, journals, and national evaluation agencies. Of course, making data accessible does not necessarily mean that it has to be shared without restrictions; always remember the motto 'as open as possible, as closed as necessary'. Thus, before uploading your data to an open access repository, ensure that you decide on the level of access that you grant to users (whether fully open or restricted) and on the license to be applied on your data. Nevertheless, sharing data without making it reusable is useless: always ensure that the data you are uploading into an open repository is FAIR and it was treated ethically and responsably, and provide all the necessary contextual documentation (both in the metadata and in the README file) to make your data understandable.
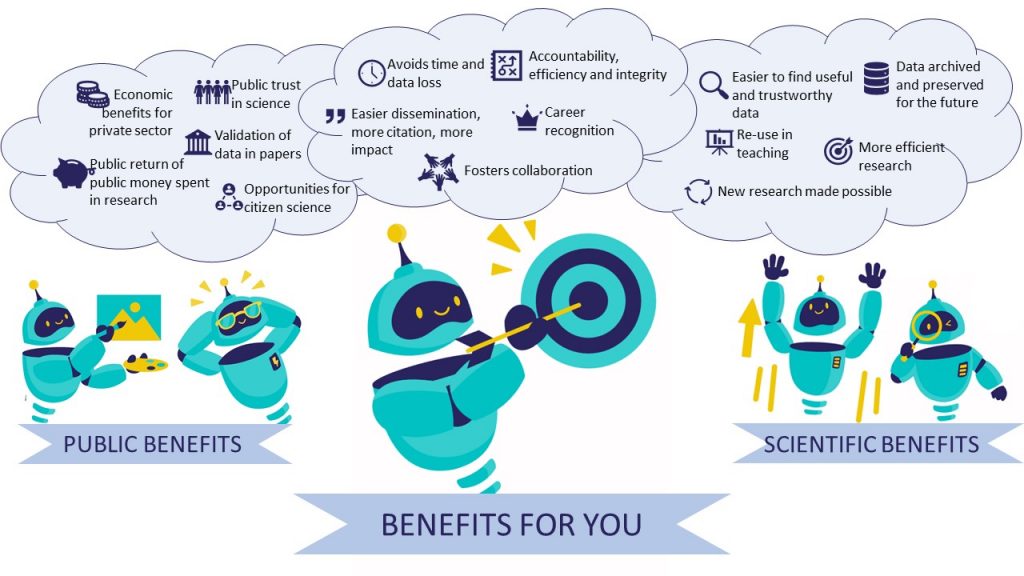
Indeed, to perform a proper and effective research data management it is crucial to always bear in mind the internationally shared FAIR principles and research ethical standards necessary to promote the values such as trust, accountability, mutual respect, and fairness. Importantly, responsible and FAIR research data management represents a cultural change in the way stakeholders in the research, education and knowledge exchange communities create, store, share and deliver the outputs of their activity: this will bring not only benefits to you, as a single researcher and the first-reuser of your own data, but also to entire scientific community and to the wider public.

Importantly, FAIR data management is a significative part of the Open Science environment, and the University of Milan:
- is committed to adopt the highest standards for data collection, storage and preservation;
- has established a Data Management Policy to formalise the full adherence to FAIR principles as a prerequisite for transparency, reproducibility and accessibility of research findings; and to establish the responsibilities, rights and duties of the University and of its researchers;
- proposes a Data Management Plan (DMP) model for data collection, documentation, storage, access, use and preservation;
- provides its researchers with the FAIR research data repository Data@UNIMI to archive and publish their datasets.